


SM
SMTR
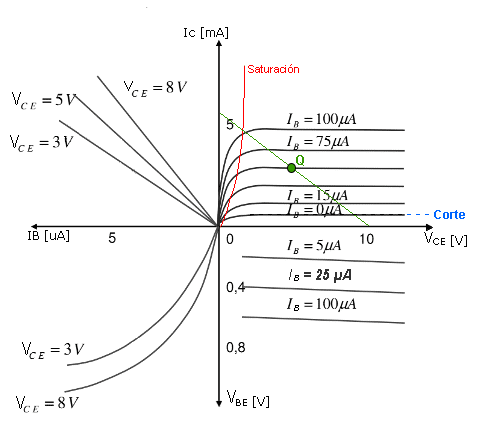
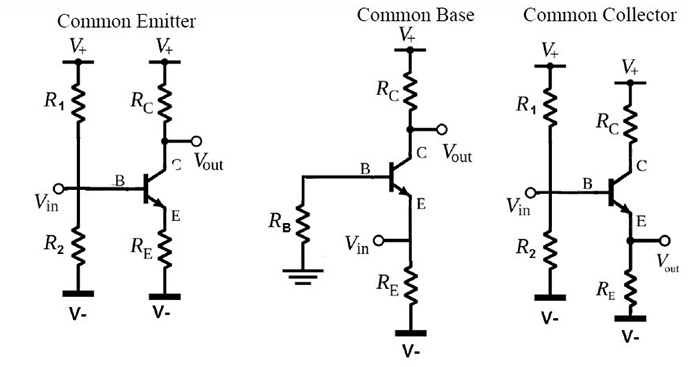
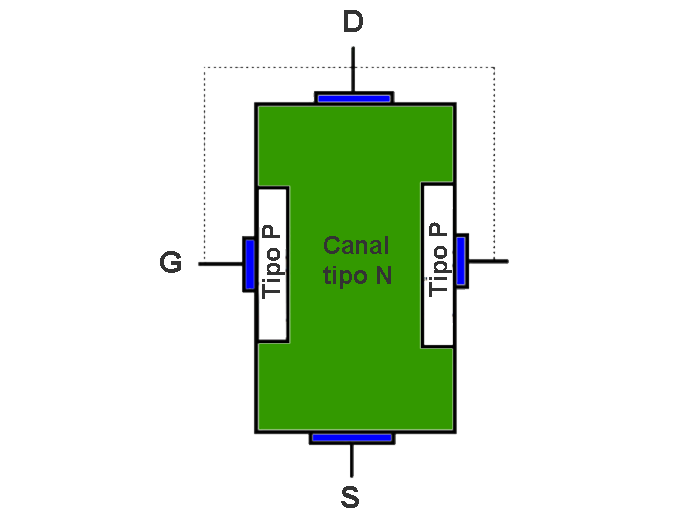
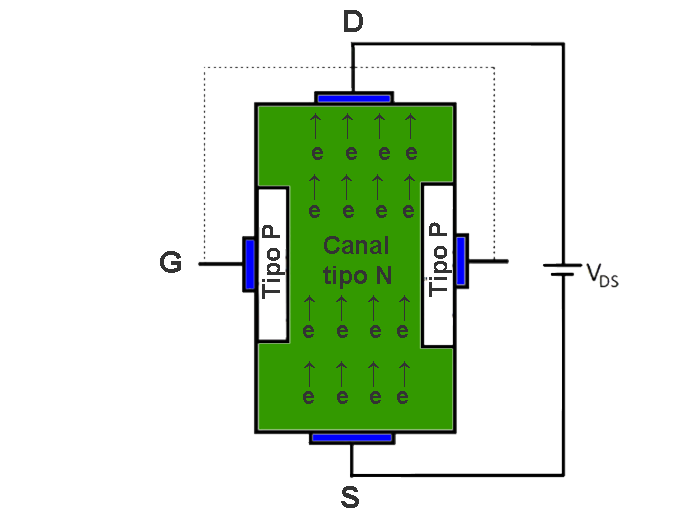
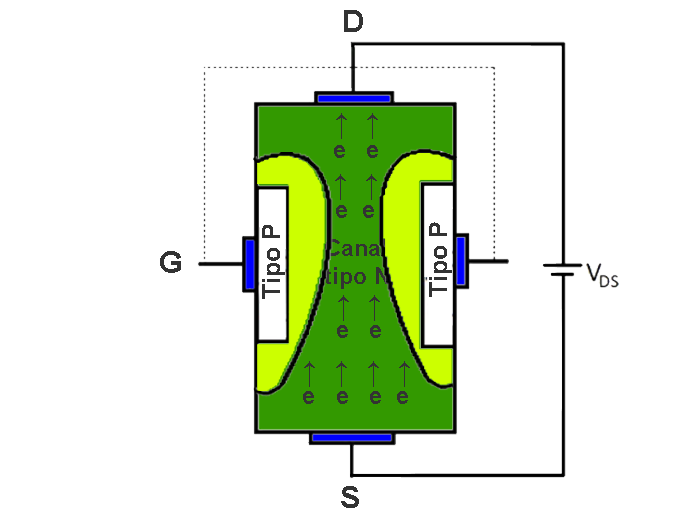
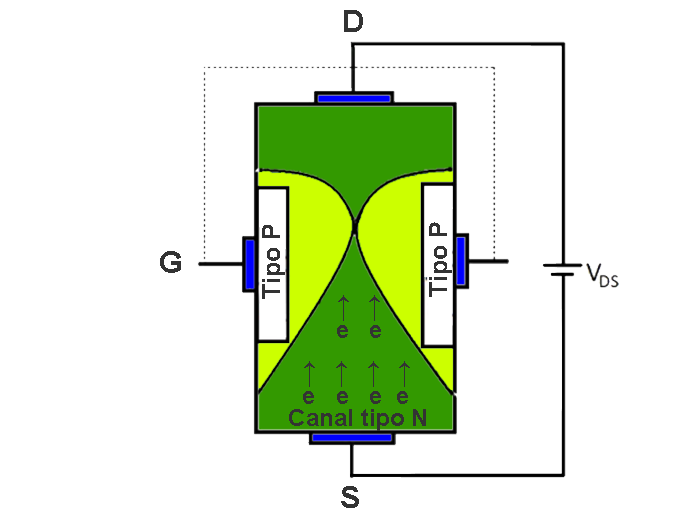
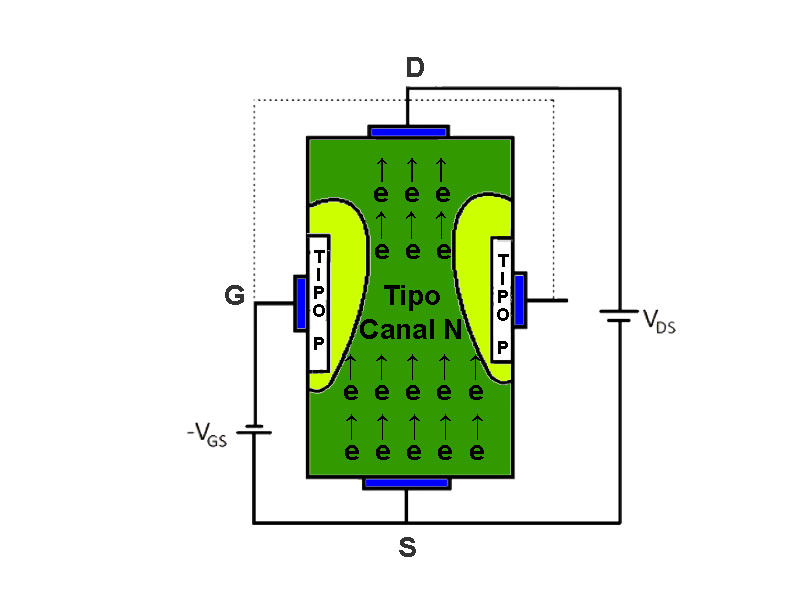
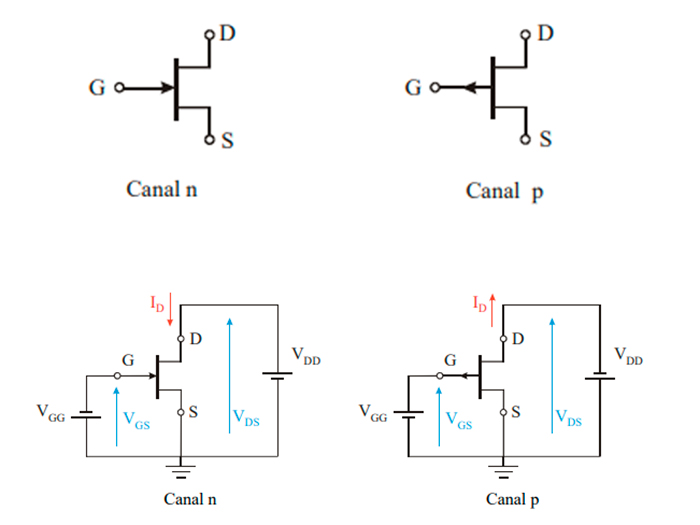
The transistor is a semiconductor that revolutionized electronics. There are different types of transistors such as bipolar transistors, mosfet transistors, and igbt.
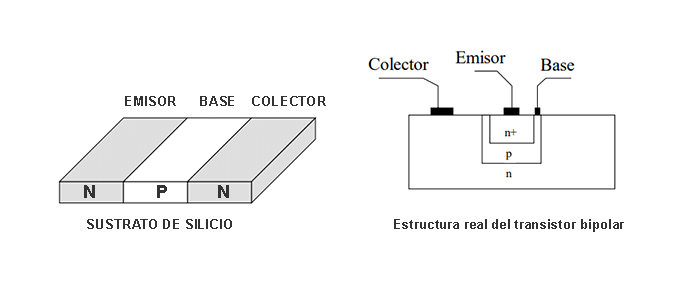
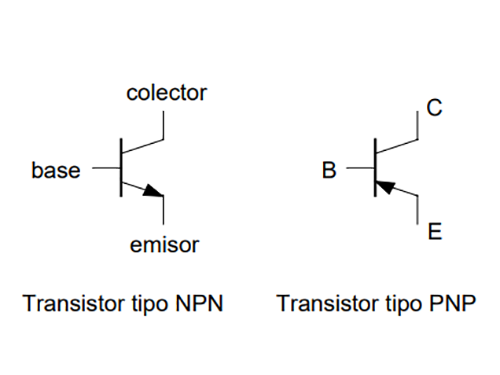
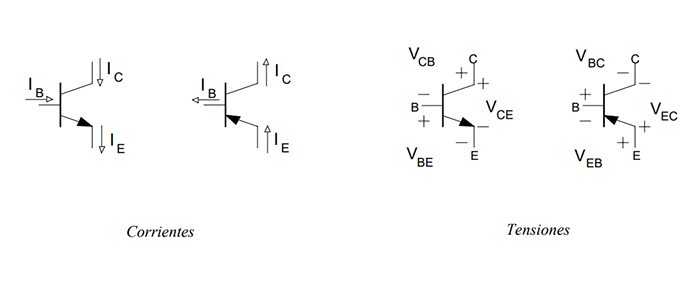
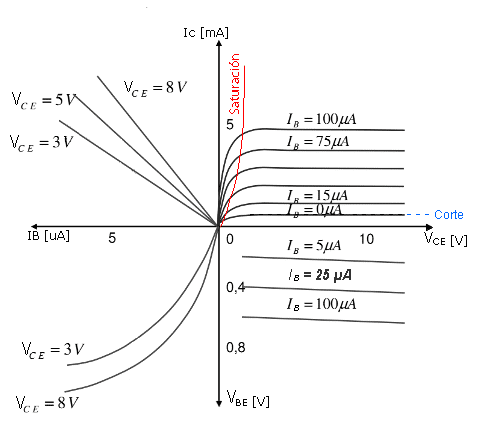
470
CDIL
3
DIOTEC
1
Hi-Sincerity
1
Infineon Technologies
4
IXYS
4
Microchip
2
Motorola
1
NTE Electronics
1
On-Semi
6
Siemens
1
STMicroelectronics
4
Vishay
2
WAYON
1
PCB
498
Stud Mount
3
Superficial (SMT)
12
Through Hole (THT)
489
DIP 8
1
FLK
1
SO-08
3
SOT-23
7
SOT-25
2
TO-1
6
TO-106
2
TO-126
40
TO-18
37
TO-202
6
TO-218
3
TO-220
110
TO-247
18
TO-3
50
TO-36
2
TO-39
58
TO-5
35
TO-50
1
TO-56
1
TO-66
2
TO-71
1
TO-72
6
TO-92
109
Dual MOSFET
2
FET N-Channel
3
N-Channel MOSFET
57
NPN BJT
226
NPN Darlington BJT
15
NPN-PNP BJT
1
P-Channel MOSFET
4
PN UJT
1
PNP BJT
185
PNP Darlington BJT
6
Nut + Lug Terminal
3
SMT Surface
3
THT Through Hole
495
0.5 mA
1
1 mA
2
2.5 mA
1
5 mA
4
6 mA
1
7 mA
1
10 mA
12
15 mA
3
20 mA
14
25 mA
8
30 mA
22
40 mA
2
50 mA
21
100 mA
67
150 mA
6
200 mA
23
230 mA
1
0.23 A
1
250 mA
2
300 mA
6
0.35 A
1
350 mA
2
400 mA
3
500 mA
29
600 mA
7
700 mA
3
800 mA
7
1 A
34
1.5 A
6
2 A
17
2.5 A
7
2.6 A
1
3 A
15
3.1 A
1
4 A
21
5 A
10
5.5 A
3
6 A
11
7 A
4
7.5 A
1
8 A
23
9 A
1
9.5 A
1
10 A
23
10.5 A
1
12 A
7
14 A
3
15 A
14
16 A
5
17 A
1
18 A
1
19 A
1
20 A
5
21 A
1
22 A
1
24 A
1
25 A
2
30 A
4
33 A
1
39 A
1
40 A
1
41 A
2
43 A
1
46 A
1
49 A
1
50 A
2
60 A
1
68 A
1
71 A
1
72 A
1
74 A
1
80 A
1
110 A
1
130 A
2
140 A
1
162 A
1
180 A
1
200 A
1
210 A
1
340 A
1
2 V
1
3 V
1
10 V
2
12 V
4
15 V
8
16 V
1
18 V
2
20 V
36
22 V
2
25 V
31
30 V
43
32 V
3
35 V
9
40 V
40
45 V
37
50 V
18
55 V
11
60 V
48
65 V
4
70 V
5
75 V
3
80 V
22
90 V
3
100 V
48
110 V
1
115 V
2
120 V
5
135 V
1
140 V
3
145 V
1
150 V
9
160 V
2
165 V
1
180 V
3
200 V
16
220 V
1
225 V
1
250 V
7
275 V
1
300 V
12
325 V
1
350 V
2
375 V
1
400 V
13
450 V
6
500 V
7
600 V
4
700 V
11
800 V
4
1000 V
1
1500 V
3
PCB
498
Stud Mount
3
60 mW
1
145 mW
1
150 mW
1
175 mW
1
200 mW
8
250 mW
17
260 mW
1
300 mW
95
330 mW
2
350 mW
6
360 mW
2
400 mW
15
500 mW
26
600 mW
11
625 mW
9
700 mW
1
800 mW
22
900 mW
1
1 W
22
1.2 W
1
1.75 W
1
1.8 W
1
3 W
3
5 W
10
7 W
1
10 W
1
12 W
1
12.5 W
24
20 W
1
25 W
2
30 W
10
40 W
14
43 W
1
50 W
4
60 W
9
65 W
8
70 W
6
75 W
3
80 W
31
88 W
1
90 W
11
94 W
2
100 W
17
115 W
1
117 W
1
120 W
14
125 W
12
150 W
32
160 W
1
170 W
1
175 W
1
180 W
1
200 W
21
300 W
10
500 W
1
0 #
2
15 #
13
20 #
50
25 #
7
30 #
22
35 #
2
40 #
42
50 #
13
60 #
23
70 #
3
75 #
4
80 #
6
90 #
2
100 #
53
120 #
21
140 #
1
150 #
48
160 #
14
175 #
1
200 #
41
250 #
8
300 #
4
400 #
1
420 #
1
460 #
2
500 #
2
750 #
7
800 #
5
1000 #
10
0.2 V
105
0.3 V
29
0.4 V
46
0.5 V
49
0.6 V
2
1 V
37
1.1 V
1
1.5 V
72
2 V
16
1 MHz
3
4 MHz
3
5 MHz
2
6 MHz
1
8 MHz
2
10 MHz
1
15 MHz
2
30 MHz
2
40 MHz
2
50 MHz
2
55 MHz
1
60 MHz
2
80 MHz
2
100 MHz
4
115 MHz
1
150 MHz
5
175 MHz
1
200 MHz
2
230 MHz
3
250 MHz
2
275 MHz
1
300 MHz
3
350 MHz
1
400 MHz
2
500 MHz
1
550 MHz
1
2.5 mΩ
1
3 mΩ
1
4 mΩ
3
4.5 mΩ
1
5.5 mΩ
1
6 mΩ
2
7 mΩ
2
8 mΩ
2
13 mΩ
1
15 mΩ
3
18 mΩ
1
20 mΩ
2
22 mΩ
4
30 mΩ
1
35 mΩ
1
40 mΩ
2
44 mΩ
1
50 mΩ
3
55 mΩ
1
60 mΩ
1
70 mΩ
2
80 mΩ
3
85 mΩ
3
117 mΩ
1
120 mΩ
1
150 mΩ
1
160 mΩ
1
180 mΩ
1
250 mΩ
1
280 mΩ
1
380 mΩ
1
400 mΩ
3
540 mΩ
1
550 mΩ
3
600 mΩ
1
800 mΩ
2
850 mΩ
1
1.6 Ω
1
3.2 Ω
1
8 Ω
1
2 V
17
2.5 V
1
3 V
15
3.2 V
1
3.5 V
1
4 V
29
6 V
1
20 V
1
150 V
62
Gallium Arsenide
1
Germanium
24
Silicon
475
